Podcast Self-Reference Ratio: 30 Hosts Ranked

Some hosts frame everything through personal experience — "I tried this," "That happened to me." Others stay in second-person mode — "You need to understand," "Tell me about your process." Neither approach is inherently better. They just serve different purposes.
We wanted to measure this difference, so we built a metric: the Self-Reference Ratio. It counts how often a host uses first-person pronouns (I, me, my) relative to second-person pronouns (you, your) during their speaking time.
What this is not: A personality test. Research by psycholinguist James Pennebaker has shown that high first-person pronoun usage correlates with honesty and lower social status, not self-absorption. A host who says "I" a lot might be building rapport through personal anecdotes, using self-deprecating humor, or framing questions through experience. A host who says "you" a lot might be giving commands, asking probing questions, or just saying "you know" a lot. The ratio captures speaking patterns. What those patterns mean depends on context.
The method
We took 20 recent episodes each from 30 podcasts — a mix of popular interview shows, comedy hangouts, and a few niche formats for contrast — and ran AI speaker diarization (WhisperX + pyannote) to isolate each host's speech. Then we counted every first-person pronoun (I, me, my, mine, myself, I'm, I've, I'd, I'll) and compared it against second-person pronouns (you, your, you're, you've, etc.).
Self-Reference Ratio = self-references / (self-references + guest-references).
- 1.0 = only first-person pronouns
- 0.5 = evenly balanced
- 0.0 = only second-person pronouns
Episodes were selected from the last 90 days, chronologically — no cherry-picking.
Bidirectional intent filtering
A raw pronoun count has flaws in both directions:
Self-ref with guest intent: "I love what you said" contains "I" but is guest-directed. We filter 30+ patterns like "I think you," "I believe you," "I appreciate your" — when detected, the "I" is not counted as a self-reference.
Guest-ref as filler: "you know" is the most common verbal filler in English and rarely addresses the guest. We filter it (along with "you know what I mean" and "you see") so it doesn't inflate guest-reference counts.
Caveat: Our filter catches 4 filler patterns. That's not exhaustive. Theo Von had 612 "you know"s filtered, which moved his ratio by 0.075 points. Other unfiltered fillers are certainly present. Take rank differences within ~0.03 of each other with a grain of salt.
The ratio vs. volume
The ratio normalizes for volume, which hides something important. A host who says "I" 10 times and "you" 10 times scores 0.50 — same as a host who says "I" 1,000 times and "you" 1,000 times. That's why we include self-refs per minute alongside the ratio. Huberman scores 0.499 at 3.8/min. Bridger Winegar scores 0.726 at 14.2/min. Winegar's speech is nearly 4x more pronoun-dense in both directions — the ratio alone can't show that.
Two dimensions, not one
The bigger story isn't who ranks #1. It's that how much a host talks and what they say when talking are largely independent.
The chart below plots every host on two axes: host talk-time (x) and self-reference ratio (y).
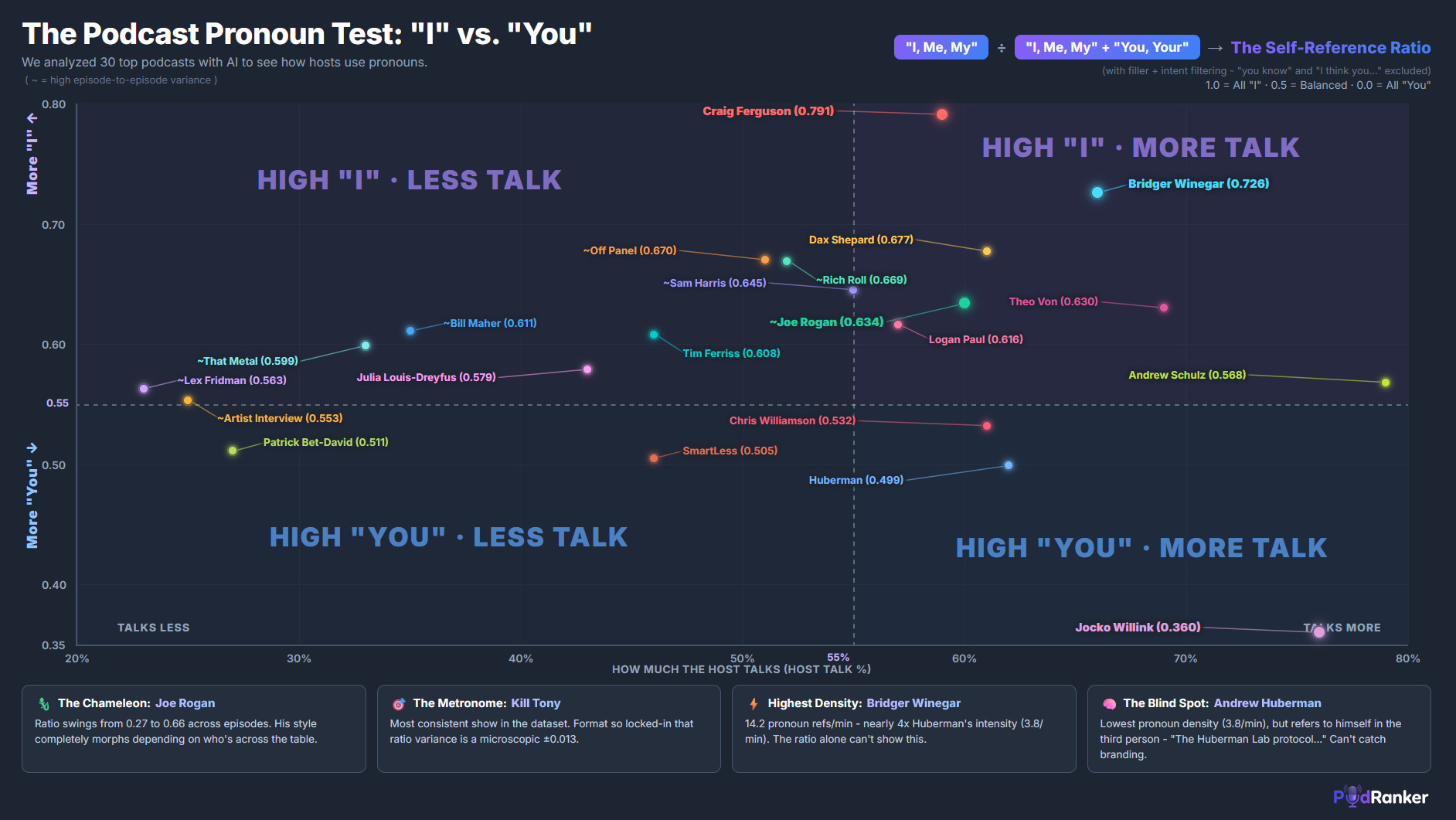
The four quadrants tell different stories:
High talk-time, high ratio — Craig Ferguson (59% talk, 0.791), Dax Shepard (61%, 0.677), Theo Von (69%, 0.630). These hosts share personal stories and use self-disclosure to draw guests out.
High talk-time, low ratio — Jocko Willink (76% talk, 0.360). Talks most of the time but almost entirely in second-person: "you need to," "you have to." Directive speech, not sharing.
Lower talk-time, high ratio — Sam Harris (55% talk, 0.645), Rich Roll (52%, 0.669). When these hosts speak, it's more introspective. But they give the guest more airtime overall.
Lower talk-time, low ratio — Patrick Bet-David (27% talk, 0.511), SmartLess (46%, 0.505). Close to balanced on both dimensions.
There is no "right" quadrant. Craig Ferguson's high ratio reflects personal vulnerability that creates intimacy. Jocko's low ratio reflects commanding instruction that serves his audience. The dimensions describe style, not quality.
The rankings
Interview podcasts (host talks < 85%)
Hosts marked * have high episode-to-episode variance (±spread > 0.15) — their ranking is approximate. Hosts marked ** have very high variance (> 0.30) and are effectively unranked.
| # | Host / Podcast | Self-Ref Ratio | ±Spread | Range | /min | Total Self-refs | Talk % |
|---|---|---|---|---|---|---|---|
| 1 | Craig Ferguson (Joy) | 0.791 | ±0.099 | 0.60–0.91 | 11.6 | 985 | 59% |
| 2 | Bridger Winegar (I Said No Gifts) | 0.726 | ±0.046 | 0.68–0.81 | 14.2 | 3,035 | 66% |
| 3 | Dax Shepard (Armchair Expert) | 0.677 | ±0.050 | 0.60–0.74 | 12.6 | 2,877 | 61% |
| 4 | Off Panel (Comics Interview) * | 0.670 | ±0.133 | 0.45–0.81 | 9.1 | 1,986 | 51% |
| 5 | Rich Roll * | 0.669 | ±0.173 | 0.40–0.83 | 8.1 | 2,156 | 52% |
| 6 | Sam Harris (Making Sense) * | 0.645 | ±0.156 | 0.37–0.80 | 7.0 | 517 | 55% |
| 7 | Joe Rogan (JRE) * | 0.634 | ±0.140 | 0.27–0.66 | 10.5 | 4,605 | 60% |
| 8 | Theo Von (This Past Weekend) | 0.630 | ±0.120 | 0.44–0.80 | 10.4 | 2,838 | 69% |
| 9 | Logan Paul (Impaulsive) | 0.616 | ±0.046 | 0.57–0.70 | 12.0 | 2,748 | 57% |
| 10 | Bill Maher (Club Random) ** | 0.611 | ±0.304 | 0.00–0.67 † | 6.0 | 939 | 35% |
| 11 | Tim Ferriss | 0.608 | ±0.122 | 0.46–0.82 | 7.7 | 1,850 | 46% |
| 12 | That Metal Interview ** | 0.599 | ±0.309 | 0.00–0.72 † | 6.9 | 275 | 33% |
| 13 | Julia Louis-Dreyfus (Wiser Than Me) | 0.579 | ±0.124 | 0.39–0.72 | 9.6 | 1,352 | 43% |
| 14 | Andrew Schulz (Flagrant) | 0.568 | ±0.043 | 0.55–0.67 | 7.5 | 3,743 | 79% |
| 15 | Lex Fridman * | 0.563 | ±0.204 | 0.46–1.00 | 6.4 | 1,395 | 23% |
| 16 | The Artist Interview * | 0.553 | ±0.185 | 0.34–0.81 | 10.1 | 607 | 25% |
| 17 | Chris Williamson (Modern Wisdom) | 0.532 | ±0.040 | 0.46–0.57 | 8.7 | 2,703 | 61% |
| 18 | Patrick Bet-David (PBD Podcast) | 0.511 | ±0.079 | 0.45–0.69 | 6.4 | 995 | 27% |
| 19 | Bateman, Arnett & Hayes (SmartLess) | 0.505 | ±0.089 | 0.42–0.65 | 9.9 | 1,215 | 46% |
| 20 | Andrew Huberman (Huberman Lab) ^ | 0.499 | ±0.078 | 0.37–0.61 | 3.8 | 939 | 62% |
| 21 | Jocko Willink (Jocko Podcast) | 0.360 | ±0.042 | 0.28–0.41 | 3.7 | 1,224 | 76% |
† A range touching 0.00 likely reflects a diarization error on one or more episodes, not genuine host behavior.
^ Huberman's ratio is likely understated — he frequently refers to himself in the third person ("The Huberman Lab protocol..."), which pronoun counting can't detect.
High-host-talk shows (>= 85%)
The host dominates airtime in these shows. Second-person pronouns are less likely to represent guest engagement when there's limited back-and-forth.
| # | Host / Podcast | Self-Ref Ratio | ±Spread | Range | /min | Total Self-refs | Talk % | Note |
|---|---|---|---|---|---|---|---|---|
| 1 | Norah Jones (Playing Along) | 0.711 | ±0.075 | 0.57–0.77 | 12.8 | 3,335 | 94% | Music segments inflate host-talk time |
| 2 | Christina P & Tom Segura (YMH) | 0.638 | ±0.055 | 0.57–0.73 | 8.5 | 2,693 | 95% | Comedy hangout |
| 3 | Audie Cornish (The Assignment) | 0.622 | ±0.060 | 0.50–0.66 | 5.7 | 634 | 97% | News narration between interview clips |
| 4 | Matt & Shane (Secret Podcast) | 0.617 | ±0.026 | 0.58–0.66 | 13.1 | 4,337 | 99% | Comedy hangout |
| 5 | Kill Tony | 0.552 | ±0.013 | 0.54–0.57 | 10.5 | 5,059 | 95% | Live comedy showcase |
What the data shows
The ratio and talk-time are independent
You might expect hosts who talk more to also self-reference more. They don't. Huberman talks 62% of the time but scores 0.499. Jocko talks 76% and scores 0.360. Sam Harris talks 55% and scores 0.645. The ratio measures what you say when you talk, not how much you talk. Two different axes entirely.
Consistency varies wildly across hosts
Andrew Schulz: ±0.043. Matt & Shane: ±0.026. Kill Tony: ±0.013. These hosts have formats so rigid that their pronoun patterns barely change.
Joe Rogan: 0.27–0.66. His ratio depends almost entirely on who's sitting across from him. Bill Maher: ±0.304 — so wide his aggregate ratio is statistically meaningless at this sample size.
Craig Ferguson and the interpretation trap
Ferguson takes the top ratio at 0.791. It's tempting to explain why — maybe he uses self-disclosure as rapport-building, maybe his Glasgow stories are conversational bait. But that's editorial interpretation, not something the data shows. What the data shows is: he uses more first-person pronouns relative to second-person pronouns than anyone else in our sample, with moderate consistency (±0.099). Anything beyond that requires actually listening to the episodes, which is a different kind of analysis.
This applies to every host on the list. The numbers describe a pattern. The meaning of the pattern is yours to interpret.
Filler filtering matters — and we probably didn't go far enough
Theo Von's 612 filtered "you know"s moved his ratio by 0.075 points. Off Panel had 462 filtered. Our 4-pattern filter is almost certainly incomplete — phrases like "you feel me" and "I was gonna say" are still in the data. The impact on hosts in the 0.50–0.65 range could be significant.
Jocko is the low-ratio extreme
0.360 with ±0.042. Despite talking 76% of the time, his speech is almost entirely directive: "you need to," "you have to." A low ratio doesn't mean guest-focused interviewing — it can also mean instruction. Style labels cut both ways.
Huberman: where the method breaks
0.499 at 3.8 self-refs/min — the lowest pronoun intensity of any host. But Huberman refers to himself through his brand: "The Huberman Lab protocol suggests." Pronoun counting can't detect that. He's probably the best example of why this metric is a starting point, not a conclusion.
Technical details
Dataset: Recent episodes from 30 podcasts, all published within the last 90 days (November 2025 – February 2026).
Pipeline: Episode download via RSS, speaker diarization (WhisperX + pyannote), first-speaker host identification, pronoun counting with bidirectional intent filtering (30+ guest-directed patterns, 4 filler patterns), talk-time classification (>= 85% separated; < 20% flagged).
Limitations worth knowing about:
- High-variance hosts (marked * and **) could shift substantially with more data. Rankings within ~0.03 of each other aren't meaningfully different.
- Filler filtering is incomplete. A single unfiltered phrase moved one host by 0.075 points. Uncaught fillers likely affect mid-table rankings.
- The ratio loses volume. Read the /min column alongside it — two hosts can score 0.50 with very different pronoun densities.
- A niche comics podcast and JRE have different production styles, audiences, and norms. The ranking shares one metric, not a common standard.